About Us
Who We Are
Stonefield Farm History
Frequently Asked Questions
Impact & Financials
Staff & Board
Press & Recognition
>
Printed Press
Audio & Video Press
Partners
>
Farm Partners
Food Access Partners
Funders
Contact Us
Programs
Food Access
>
Gleaning
Receiving Produce
Transportation Services
Boston Food Hub
Apprenticeship
Get Involved
Volunteer
Job Opportunities
Banana Box Collecting
Events
Support Us
Donate
Shop Gleaners Merch
Resources
Food Resources
Meet the Veggies
Blog
News & Reports
2022 Recipe Share
Volunteer
MAKE A GIFT
About Us
Who We Are
Stonefield Farm History
Frequently Asked Questions
Impact & Financials
Staff & Board
Press & Recognition
>
Printed Press
Audio & Video Press
Partners
>
Farm Partners
Food Access Partners
Funders
Contact Us
Programs
Food Access
>
Gleaning
Receiving Produce
Transportation Services
Boston Food Hub
Apprenticeship
Get Involved
Volunteer
Job Opportunities
Banana Box Collecting
Events
Support Us
Donate
Shop Gleaners Merch
Resources
Food Resources
Meet the Veggies
Blog
News & Reports
2022 Recipe Share
Volunteer
MAKE A GIFT
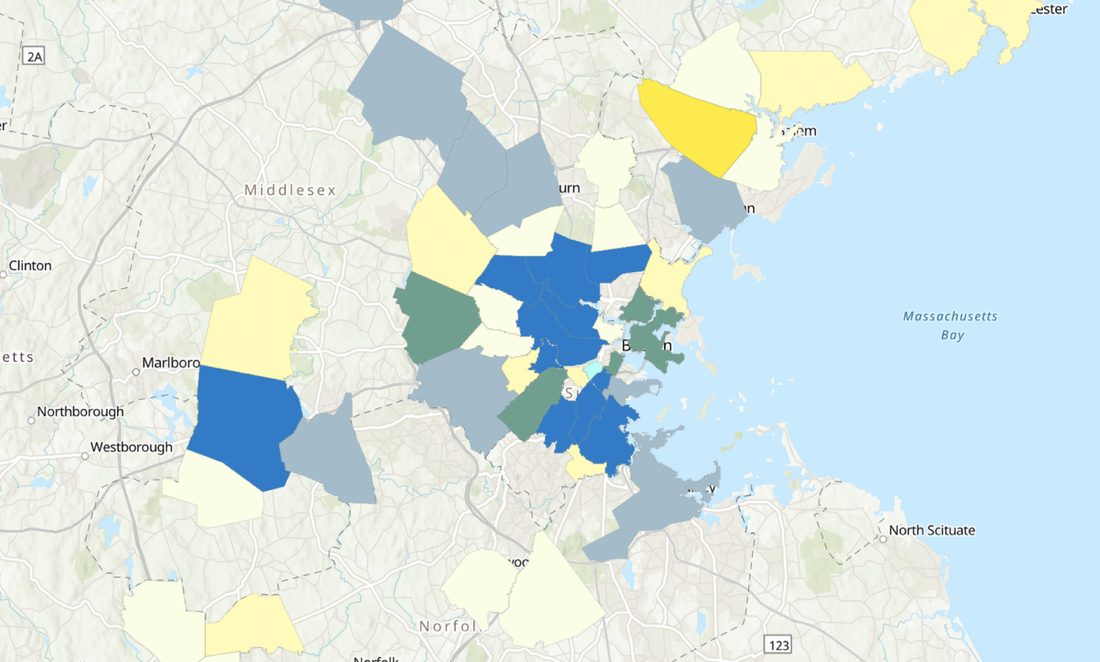
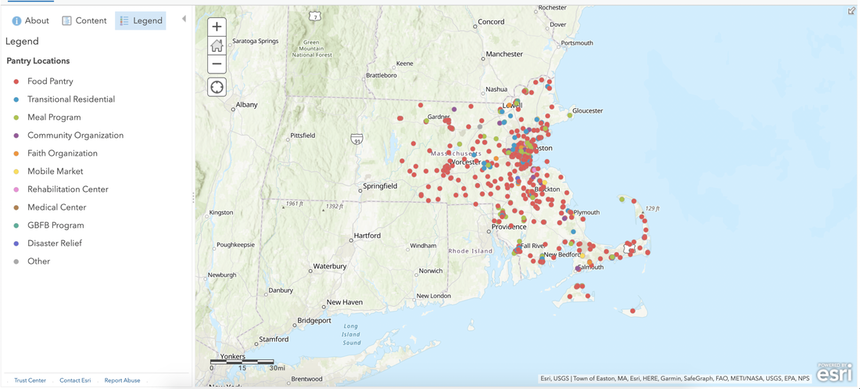
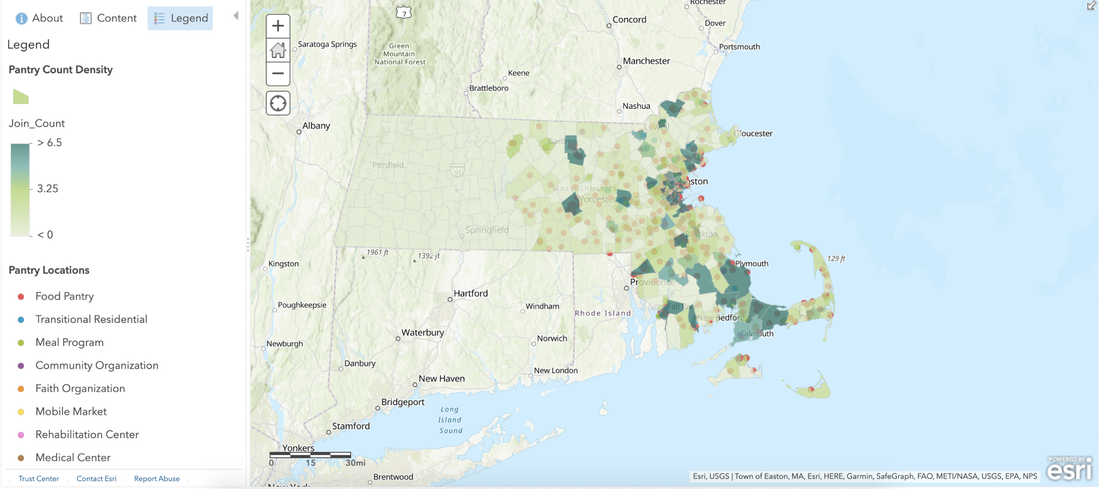
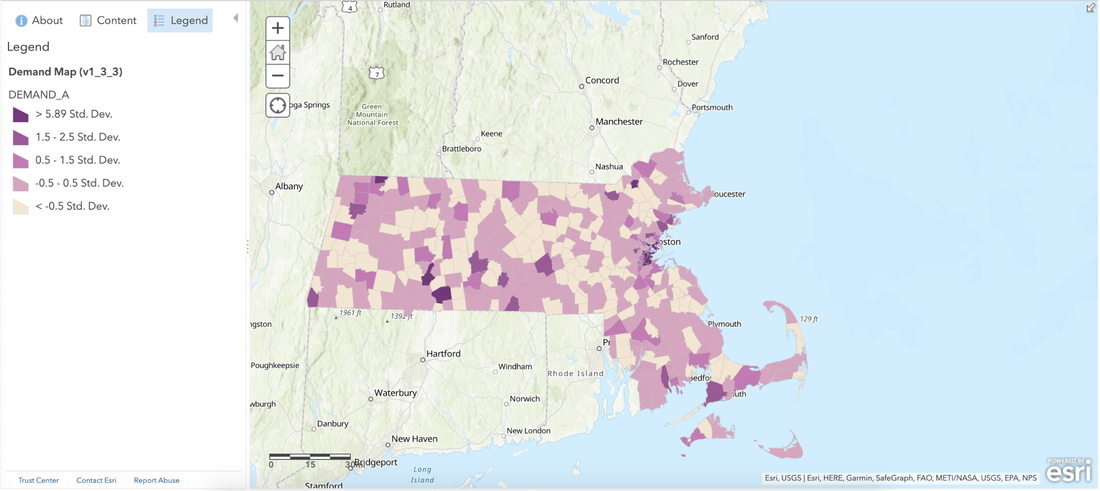
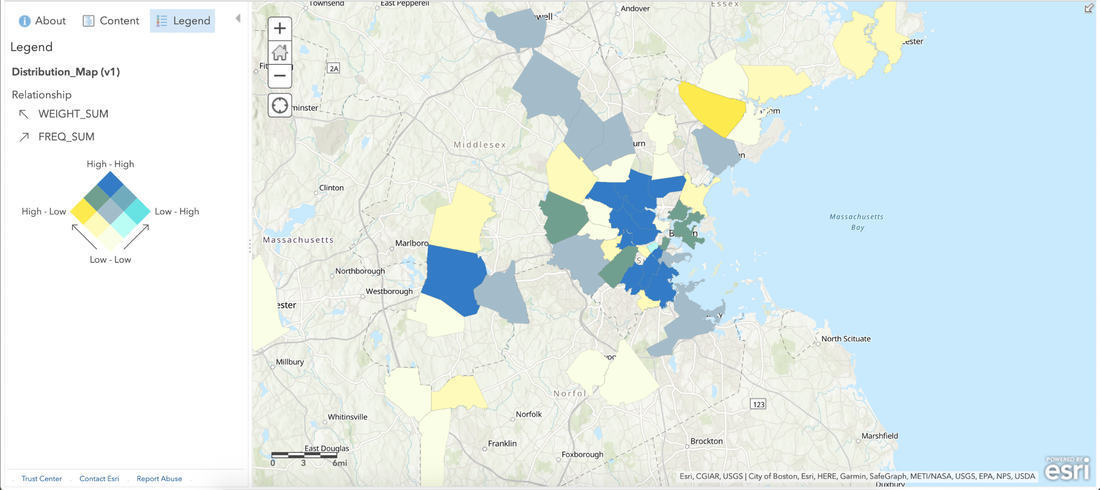
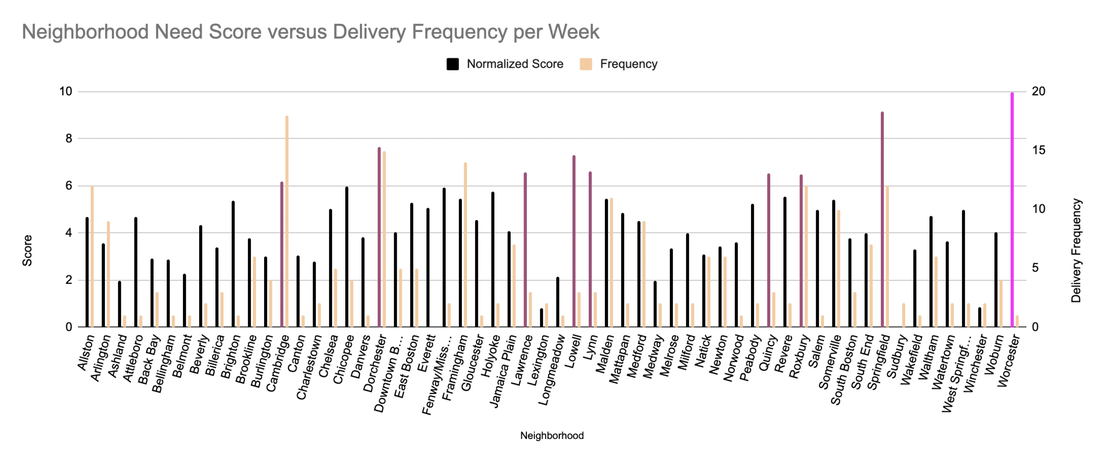

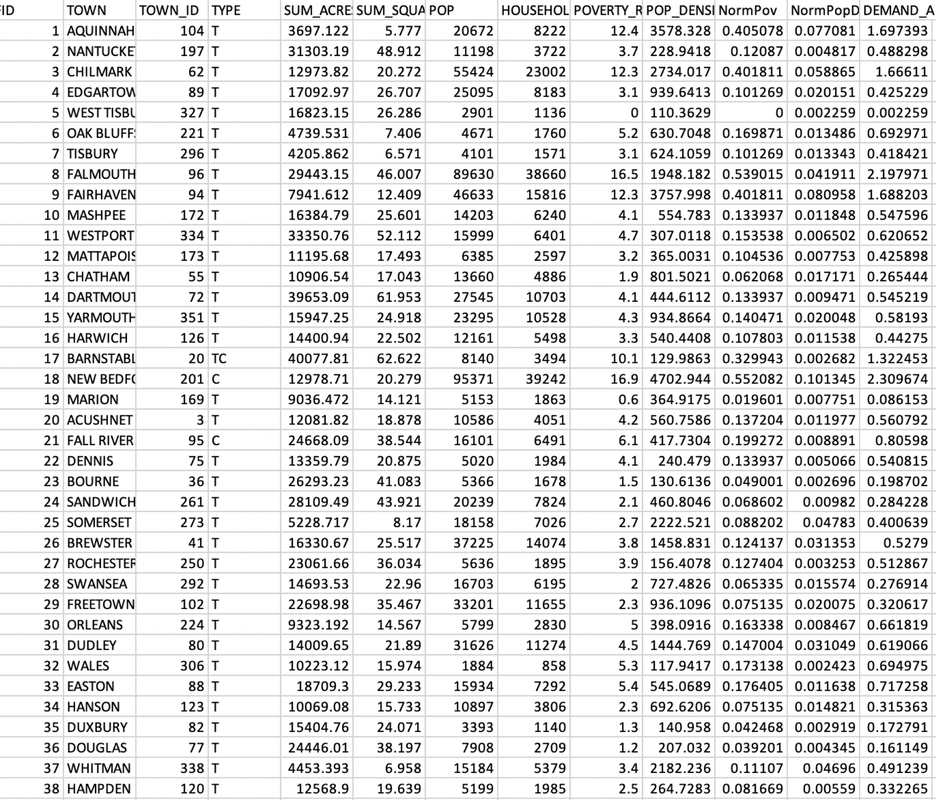
 RSS Feed
RSS Feed